For those already familiar with Oracle EPM integration, you’ll know it provides a built-in file archiving process. Essentially, after your file is loaded by Data Management, the archival process creates a copy for future reference during debugging or auditing.
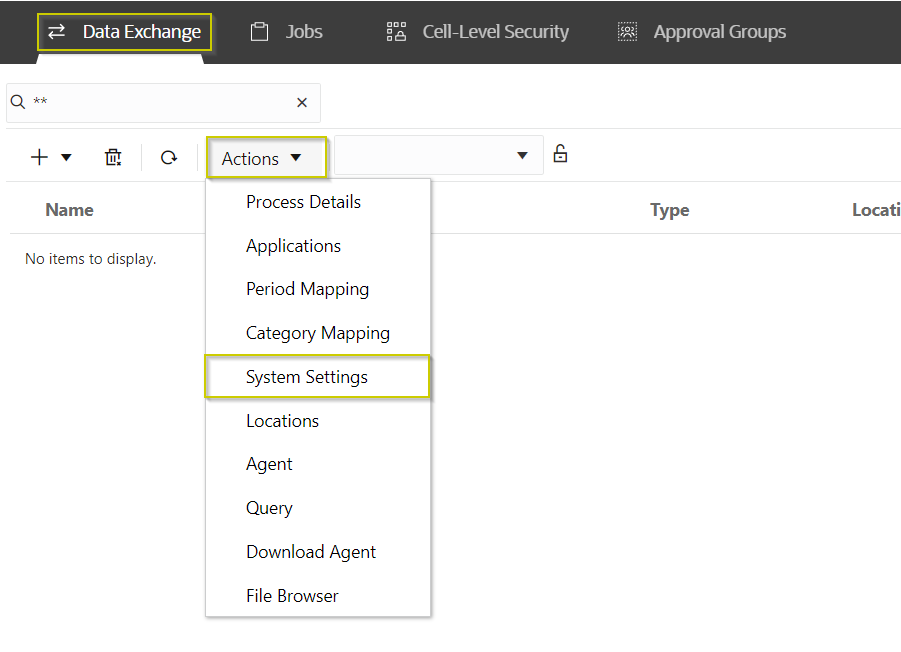
Built-in Archival Process: Lets see the options:
Lets look into the system settings:
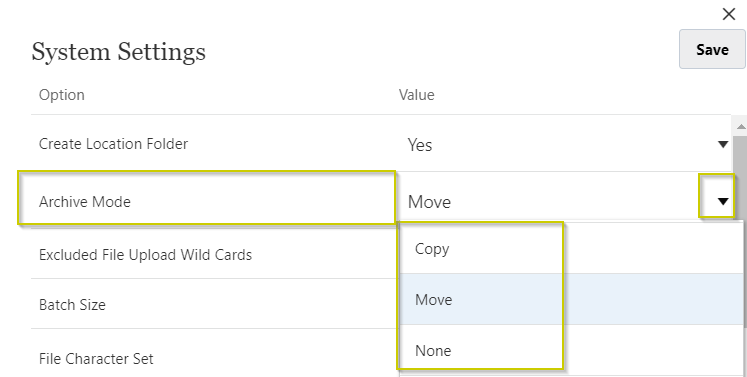
- Copy – creates a separate archived copy of the file
- Move – removes the processed file from its original location and places it in the archive
- None – disables the file archiving feature
How to Access the archived files
All the archived files will be in the default data directory. There are two ways to access the file.
- From Workbench
- From EPM Automate
It’s important to understand the naming convention for archived file names in Oracle EPM data integration. By default, Oracle EPM data integration uses the following naming convention:.
<Process ID><Year><Month><Day>.<File Extension>
The year, month, and day for the file name are derived from the processed data load period mapping. Since your process ID is unique, the filename will always be unique as well.
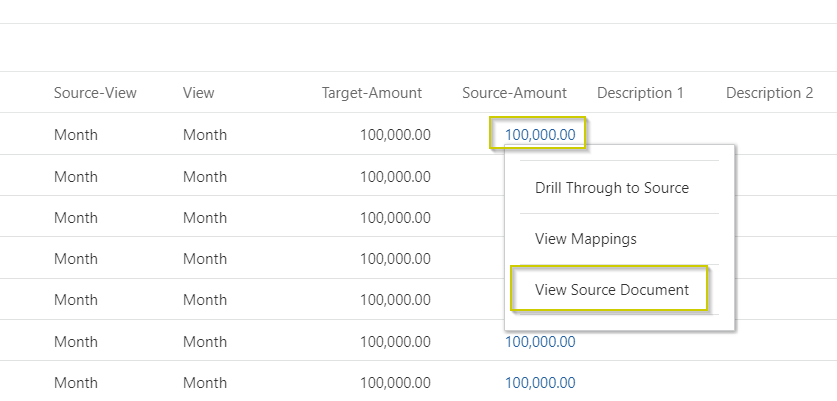
1. Accessing From Workbench
In the workbench, navigate to the desired record. Click on the hyperlink within the source amount/data column, then select View Source Document. This would download the source file to your local machine.
While the workbench method is ideal for accessing recently processed files, retrieving older archived files might require a different approach.
2. Accessing From EPM Automate
Knowing the process ID simplifies accessing the processed file. With the naming convention in mind, you can locate the file within the data directory, as all archived files reside there.
I attempted to access the data directory from the front end, but was unsuccessful. If anyone has knowledge of the appropriate access procedures, please let me know.
here is the list files snippet that I use to locate my archived files.

Output:
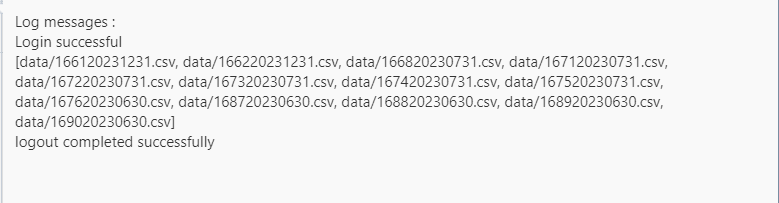
Lets use local EPM Automate to download the files.
With the process ID and period in hand, can we easily retrieve the original processed filenames? It’s important to note that Oracle likely purges these files after a number of days. Refer to the documentation for details.
But why does anyone need a custom process?
The current archival process works well for most situations. However, I recently received a request for a more specific archiving method. The requirement is to archive a file in a designated folder within the Data Management inbox directory. Additionally, the filename should include a date and time stamp. This archived file will be accessed by an external system and serve as a long-term backup outside of the EPM environment.
The built-in archival process is pretty much locked out except the three options. So I had to create a custom process using alternate approaches.
Pipelines?
Pipelines offer powerful file operation functions like copy, delete, and move. Could we leverage a pipeline to trigger the file archiving process after Data Management finishes processing the file? yes. but how do you pass the date and time stamp to the file operation object within pipelines?
Substitution Variables?
Substitution variables are currently the only object to interact with pipeline variables as of now. It’s interesting to note how substitution variables have remained relevant despite being around for a long time
we could leverage substitution variables to store the future filename with the date and timestamp. Then, we could use that variable within the pipeline.
Groovy?
So how to get the latest timestamp into the substitution variable? This is where Groovy can be helpful. We can use Groovy businessrule within the pipeline to generate the timestamp and then assign it to the substitution variable.
Execution
Pipeline:
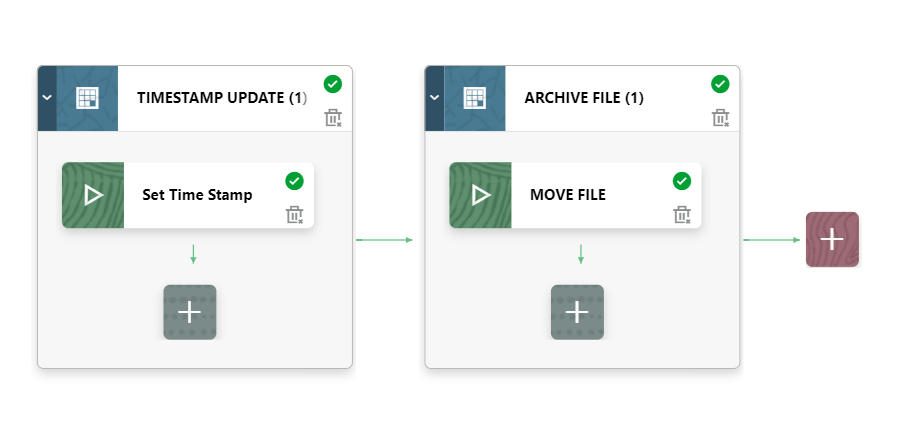
Copy File Operation:
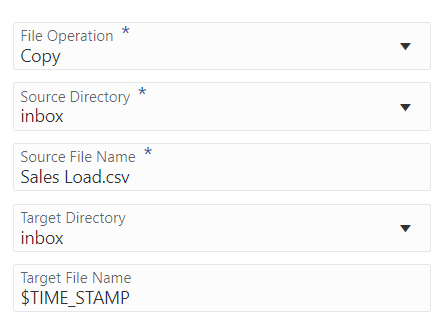
Log File:

The built-in archive in Oracle EPM works well, but sometimes you need more control. Pipelines are a powerful tool that can be used to move and rename files after they’re processed. By combining pipelines with Groovy scripting, you can even automatically add timestamps to filenames. This lets you customize the archiving process for your specific needs. So, next time you have a unique archiving requirement, remember pipelines and Groovy! If you get creative, substitution variables can act as a bridge between your applications and integrations, opening up even more possibilities. I hope this information is helpful.
Comments
2 responses to “EPM Integration – Building a Custom File Archival Process with Pipelines for File-Based Integrations”
We have used the custom archival process along with Groovy Pipeline for various clients. Pipeline + Groovy is powerful.
very creative. any thoughts about archiving to Oracle Object Store?